
In the spring of 2017, the Centers for Disease Control (CDC) and their Canadian equivalent, the Public Health Agency of Canada launched The Healthy Behavior Data Challenge. This challenge was intended to help update the current methods of public health surveillance by exploring how modern technologies could be used to capture real-world and real-time data on behaviors relevant to public health. We were excited to see this challenge taking place we know firsthand the power of using wearable sensors to measure and understand health behaviors.
Fast forward to this year, and we're excited to have played a roll in helping eventual winner, RTI International, create a novel and impactful method for capturing important behavioral data from the wearable devices used in everyday life by millions of Americans. Last week, after the winners were announced we took some time to chat with the principal investigator, Dr. Robert Furberg, about the challenge, their project, and what he sees as the future of public health surveillance.
 Your project at RTI International just won the US Healthy Behavior Data Challenge by showing how large amounts Fitbit data can help us better understand population health trends. Can you tell us a bit more about it?
Your project at RTI International just won the US Healthy Behavior Data Challenge by showing how large amounts Fitbit data can help us better understand population health trends. Can you tell us a bit more about it?
For sure! I'll start here with a bit of context and background on the challenge itself in case it’s not familiar to some people. For starters, CDC runs this program called the Behavioral Risk Factor Surveillance System, or BRFSS. From their website:
“The Behavioral Risk Factor Surveillance System (BRFSS) is the nation's premier system of health-related telephone surveys that collect state data about U.S. residents regarding their health-related risk behaviors, chronic health conditions, and use of preventive services. Established in 1984 with 15 states, BRFSS now collects data in all 50 states as well as the District of Columbia and three U.S. territories. BRFSS completes more than 400,000 adult interviews each year, making it the largest continuously conducted health survey system in the world.”
What they don’t really convey here is that this system is a big deal. In many states, the BRFSS provides the only population-level estimates of things like obesity, smoking, and a whole slew of behaviors that contribute to an individual’s risk of developing a chronic disease. Unfortunately, the survey is still pretty old-school, methodologically, so they’ve been exploring new approaches to data collection without compromising what they already have going and what they’ve done in the past.
So, the CDC initiated the Healthy Behavior Data Challenge a little over a year ago (April 28, 2017). From the challenge.gov website:
“The Healthy Behavior Data Challenge responds to the call for new ways to address the challenges and limitations of self-reported health surveillance information and tap into the potential of innovative data sources and alternative methodologies for public health surveillance.
The Healthy Behavior Data (HBD) Challenge will support the development and implementation of prototypes to use these novel methodologies and data sources (e.g., wearable devices, mobile applications, and/or social media) to enhance traditional healthy behaviors surveillance systems in the areas of nutrition, physical activity, sedentary behaviors, and/or sleep among the adult population aged 18 years and older in the US and US territories.”
The folks at these larger federal bodies usually run these distributed technical challenges across two discrete phases - you basically propose what you’ll do in the initial stage, then you get some financial support to actually do the work. I should mention that challenges are weird and fun -- it’s kind of like writing a grant application, then doing a study, but most of the time you end up doing nearly all of the work at-risk with little guarantee of a return on the time and energy you put into it. The HBD was setup to run as a 13 week-long ideation phase, followed by about a 16 week prototyping and implementation phase. I remember finally getting all inspired on a morning flight to somewhere about a month before the ideation phase was going to end.  I sketched a really rough draft of what I wanted to do on a napkin. Naturally, I took a picture of it and posted to social media.
I sketched a really rough draft of what I wanted to do on a napkin. Naturally, I took a picture of it and posted to social media.
At the time, I had something overly ambitious in mind for this with all sorts of prospective, multichannel data collection -- intraday Fitbit measures, continuous spatial data, and Ecological Momentary Assessment (EMA) for frequent, in situ measurement of affect. Honestly, it was overkill. I submitted the required Phase 1 documentation of the concept and promptly forgot about it until I got an email from Dr. Machell Town, the branch chief for the Population Health Surveillance Branch in the Division of Population Health, National Center for Chronic Disease Prevention and Health Promotion at CDC. Her initial message totally went to my junk folder in Outlook (protip: check it often!). Anyway, her message explained that we had been selected to receive a $5K Phase 1 award, along with an invitation to submit for Phase 2.
The phase 2 submission requirements were actually pretty formidable. Again, from the challenge.gov site:
“During The Phase II Prototype Implementation Phase, the six submissions selected under Phase I will test their solutions, utilizing data from 300 or more adults (aged 18 and above) residing in the US or its territories. During this phase there will be an opportunity for HBD Challenge participants to incorporate data from existing surveys including the Behavioral Risk Factor Surveillance System (BRFSS).”
CDC invited six teams to gather data from 300 US adults and sponsored each team $5K to do the work. And here’s where the risk comes into play. There were two issues that came to mind right away. First, I knew that what I had proposed initially was way too complicated and expensive to pull it off given the resources I had available. Second, when I got to thinking about public health surveillance more conceptually, I realized that I was fundamentally opposed to anything other than retrospective data collection. I had convinced myself that anything other than this approach would result in an observer effect. Surveillance should really be a simple, clean assessment of risk factors. I was worried that if we deployed an EMA app with GPS tracking and a wearable, we’d be functioning as more of an unintentional intervention and I realized we needed to avoid this at all costs. This ended up making more sense to me over time as I reasoned that a rationale for our approach should emphasize retrospectiveness and simplicity in our data collection protocol. The more I thought about it, the more I realized that I wanted to implement a novel approach that could be scaled with as little impact on CDC’s BRFSS operations as possible. What did we do? Easy. We asked people if they had a Fitbit and used Fitabase to pull as much as we could get from their past 30 days of tracking.
In a little more detail, we designed and implemented a four part process, all of which was subject to the review and approval of our Institutional Review Board. irst, we rewrote the CDC’s public health surveillance questionnaire for self-administration; second, we implemented the survey in an open source data collection software called REDCap; third, we went out to Amazon Mechanical Turk and screened people to find those who owned a Fitbit and would be willing to share their data with us; finally, we went back to those people we had screened and had them complete the REDCap survey, then authorize data retrieval via Fitabase.
One of the most stunning things about this study was that we managed to screen over 600 eligible participants on MTurk in less than 4 hours. Data collection from nearly 300 respondents took about 12 hours once we invited them to onboard.
The goal of the challenge was to develop ways to bring traditional survey surveillance methods into the 21st century. How did you come to the conclusion that Fitbits and wearable sensor data made sense as a new adjunctive tool for public health surveillance?
Yes! I mean, I think so? I should fall back on my training and say something like “more research is needed” which also happens to be true in this case. The biggest issue and hit against our approach is probably totally obvious: Fitbit owners are not representative of the U.S. population, limiting the generalizability of these findings. Allow me to clarify.
Are there a lot of Fitbit users? Yes! There were 25M of them in 2017. Do these devices work well enough to capture certain measures? Yes! Here’s a systematic review on their performance. Can they fit into the conduct of a public health or clinical intervention? Yes! As of today, there are 272 registered clinical trials using Fitbits for data collection.
The moment you start thinking about population-level uses of these data that are unhinged from a tightly controlled sampling frame, there are three major problems that arise: sample representativeness and selection bias; poorly characterized reference populations; and spatiotemporally inconsistent denominators.
Long before this challenge was announced, we published results of an analysis last year in which we compared four pretty basic health indicators between the Fitbit Activity Index and BRFSS. The net result wasn’t pretty, but the findings had everything to do with the denominator issue. Despite these challenges, I think there’s a pretty simple solution for this: establish a nationally representative sample, distribute wearables to them for long-term use, and incentivize compliance and sustained engagement.
One of the biggest things we still need to sort out in post-processing and analysis is the concordance between self-report and the wearable data. Short of the ambitious “instrument everyone” approach think this is probably one of the most valuable things these devices offer today: a way to better quantify measurement error. If you think about it, these devices yield more objective measures of physical activity, sedentary behavior, and sleep that are otherwise burdensome to obtain via self-report and are frequently subject to recall and normative biases.
You gathered a lot of Fitbit data, what was your most interesting finding from all that objective data?
More work is needed! Can we talk about how much data we got for a sec? For our purposes, let’s go to the back of an envelope. Okay, so assuming 100% compliance and basing this on the intraday (minute-level) dataset for maximum impact, we’re trying to figure out how to wrangle and join almost 13 million data points (plus survey, plus daily summary measures, plus structured 24h epoch data).
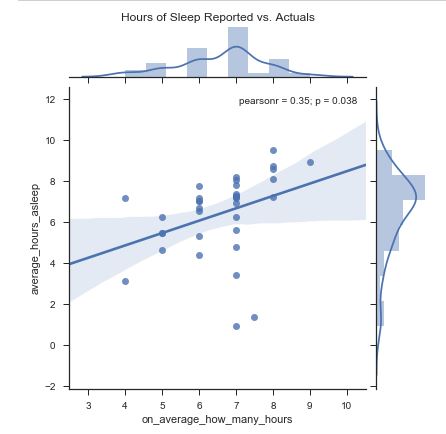 We’ve taken this opportunity to build out the remaining infrastructure to process more (larger) joint survey and device datasets. I’m a little embarrassed that our findings don’t come spilling out, but we are still actually processing all of that data. Consistent with the HBD challenge requirements, we delivered a structured dataset and data dictionary to CDC for their statisticians to review as a part of phase 2 judging. We’ve developed a few analytic appliances to help fuse the datasets, query them, and output meaningful / pretty data visualizations. Here’s a sneak peak of how we’ve wrangled continuous survey responses versus the Fitbit data. This approach enables us to visualize the relationships between survey variables or the relationships between survey variables and Fitbit variables. Most of that has been implemented in Python.
We’ve taken this opportunity to build out the remaining infrastructure to process more (larger) joint survey and device datasets. I’m a little embarrassed that our findings don’t come spilling out, but we are still actually processing all of that data. Consistent with the HBD challenge requirements, we delivered a structured dataset and data dictionary to CDC for their statisticians to review as a part of phase 2 judging. We’ve developed a few analytic appliances to help fuse the datasets, query them, and output meaningful / pretty data visualizations. Here’s a sneak peak of how we’ve wrangled continuous survey responses versus the Fitbit data. This approach enables us to visualize the relationships between survey variables or the relationships between survey variables and Fitbit variables. Most of that has been implemented in Python.
What are the next steps for this project?
Yeah, so we’ve got a few ongoing and anticipated next steps.
First, we’re trying to get a handle on conducting a larger scale demonstration project with CDC; using these methods at scale alongside the BRFSS data collection operations to demonstrate the ease with which this approach could be integrated with minimal disruption to their ongoing work.
Second, we’ve got a couple of papers in the works - the first will be on the data collection protocol and methods, the next one will be a higher-level piece on lessons learned and the potential for using these devices for public health surveillance, to include some descriptive stats.
Third, we’re cruising along on the analytic environment work I mentioned above. Getting these data is the easy part. Managing, curating, and making sense of them is considerably harder. Naturally, we’re looking at bringing some machine learning into the mix as well, but I’ll be happy if I can easily compare survey responses to wearables data by respondent.
Fourth, and possibly most exciting, is that I’m working on getting the Fitbit data into a Synthetic Population we developed at RTI to see if it can be done, then explore what kind of modeling it might support. I have long maintained that the lifecycle of sensor data could extend beyond analysis and have often wondered if there would be a way to get real people’s wearable data into a large scale agent based model. Turns out, it seems like you can. I had first started working with our brilliant GIS guys on a different HHS challenge a few years ago based on our submission to the Obesity Data Challenge. Now that I have stats on demographics and a fair amount of Fitbit data, I want to feed this into the model and revisit our comparison between the Fitbit Activity Index and BRFSS to see how the synthetic population output fares.
Do you have any other exciting Fitbit or wearable data projects you’re working on?
Yeah, we do! I can think of two pretty solid examples we’ve got going using consumer-grade sensors.
We just wrapped up a CTSA-sponsored Cardiac Rehab study in which we used Fitbits to individualize patients’ PA goals in order to better facilitate to transition out of supervised rehab and back into the home. Results were super promising and the patients loved everything about participating in the study. We’ll seek additional funding from NIH to do this again in a larger sample.
I’m also running an ancillary study on the National Longitudinal Study of Adolescent to Adult Health (Add Health) in which we’re surveying about 13,000 participants on their use of wearables and getting as many donations of historical data as we can for secondary analysis. Data collection should wrap up on that one this summer and I’m really excited about the initial results I’ve seen.
Lastly, do you have any advice for researchers looking to use consumer wearables in their research studies?
Yes! For starters, we’re all still trying to figure this stuff out. Don’t be afraid to fail because if there’s one thing to expect up front, it’s that things will work the way you have planned. Self-experiment whenever possible. This is such a dynamic and exciting angle for public health and clinical interventions, but that also means there’s high risk around every corner. SHARE WHAT YOU LEARN. Even if it’s just inside of your own organization, don’t underestimate the significance of your experience, even if it wasn’t exactly awesome. And finally, find a mentor. I wouldn’t be where I am today without all of mine. Learning from your mistakes, mitigating risk, and figuring out how to do legit, rigorous, credible digital health is not something you should try to do alone.
Thanks for taking the time to chat with us Robert! We're excited to see what you do you next.